2026.06.30
- AI ⚙️
- 技術 💻

AIコーディングのコスト高騰にどう向き合うか
高性能LLM選定におけるコスト・性能・セキュリティの考え方
生成AIの活用は、文章作成や要約だけでなく、ソフトウェア開発の現場にも広がっています。
コード生成、既存コードの調査、バグ修正案の作成、テストコードの作成、ドキュメント化など、開発業務を支援する用途は今後さらに一般的になっていくと考えられます。
一方で、実務利用が進むにつれて新しい課題も見えてきました。
その一つが、LLMの利用コストです。
AIコーディングでは、単純なチャット利用よりも大量のトークンを消費しやすくなります。
コードベース全体の読み込み、長いやり取り、修正内容の差分確認、テスト実行結果の解析などを行うため、入力・出力ともに大きくなりがちです。
高性能なモデルほど単価も高く、使い方によっては月額プランやAPI料金の見直しが必要になるケースもあります。
また、特定の高性能モデルが一時的に利用できなくなる、提供条件が変わる、価格体系が変更されるといったリスクもあります。
そのため、これからのAI活用では「どのモデルが一番賢いか」だけでなく、「業務に合ったコストで安定して使えるか」「セキュリティや社内ルールに適合するか」という観点が重要になります。
本記事では、AIコーディングにおけるLLM選定の考え方を、コスト・性能・セキュリティの観点から整理します。特定のサービスの導入を推奨するものではなく、業務利用を検討する際の確認材料としてご覧ください。
コード生成、既存コードの調査、バグ修正案の作成、テストコードの作成、ドキュメント化など、開発業務を支援する用途は今後さらに一般的になっていくと考えられます。
一方で、実務利用が進むにつれて新しい課題も見えてきました。
その一つが、LLMの利用コストです。
AIコーディングでは、単純なチャット利用よりも大量のトークンを消費しやすくなります。
コードベース全体の読み込み、長いやり取り、修正内容の差分確認、テスト実行結果の解析などを行うため、入力・出力ともに大きくなりがちです。
高性能なモデルほど単価も高く、使い方によっては月額プランやAPI料金の見直しが必要になるケースもあります。
また、特定の高性能モデルが一時的に利用できなくなる、提供条件が変わる、価格体系が変更されるといったリスクもあります。
そのため、これからのAI活用では「どのモデルが一番賢いか」だけでなく、「業務に合ったコストで安定して使えるか」「セキュリティや社内ルールに適合するか」という観点が重要になります。
本記事では、AIコーディングにおけるLLM選定の考え方を、コスト・性能・セキュリティの観点から整理します。特定のサービスの導入を推奨するものではなく、業務利用を検討する際の確認材料としてご覧ください。
低コストLLMが選択肢として注目される背景
近年、DeepSeek、GLM、Qwenなど、中国発のLLMも注目されています。
これらのモデルの一部は、API料金、長いコンテキスト長、コーディング性能、オープンウェイトでの提供などを特徴としており、従来の高性能LLMに対する新しい選択肢になりつつあります。
特にAIコーディングでは、以下のような用途で低コストモデルの価値が出やすくなります。
* 既存コードの調査
* リファクタリング案の作成
* テストコードの生成
* エラー原因の分析
* ドキュメント作成
* 大量ファイルの要約
* 長時間のエージェント実行
こうした作業では、必ずしも常に最高価格帯のモデルを使う必要はありません。
重要な設計判断やセキュリティに関わる部分では高性能モデルを使い、調査・下書き・要約・テスト補助などでは低コストモデルを使う、といった使い分けが現実的です。
これらのモデルの一部は、API料金、長いコンテキスト長、コーディング性能、オープンウェイトでの提供などを特徴としており、従来の高性能LLMに対する新しい選択肢になりつつあります。
特にAIコーディングでは、以下のような用途で低コストモデルの価値が出やすくなります。
* 既存コードの調査
* リファクタリング案の作成
* テストコードの生成
* エラー原因の分析
* ドキュメント作成
* 大量ファイルの要約
* 長時間のエージェント実行
こうした作業では、必ずしも常に最高価格帯のモデルを使う必要はありません。
重要な設計判断やセキュリティに関わる部分では高性能モデルを使い、調査・下書き・要約・テスト補助などでは低コストモデルを使う、といった使い分けが現実的です。
料金比較から見えること
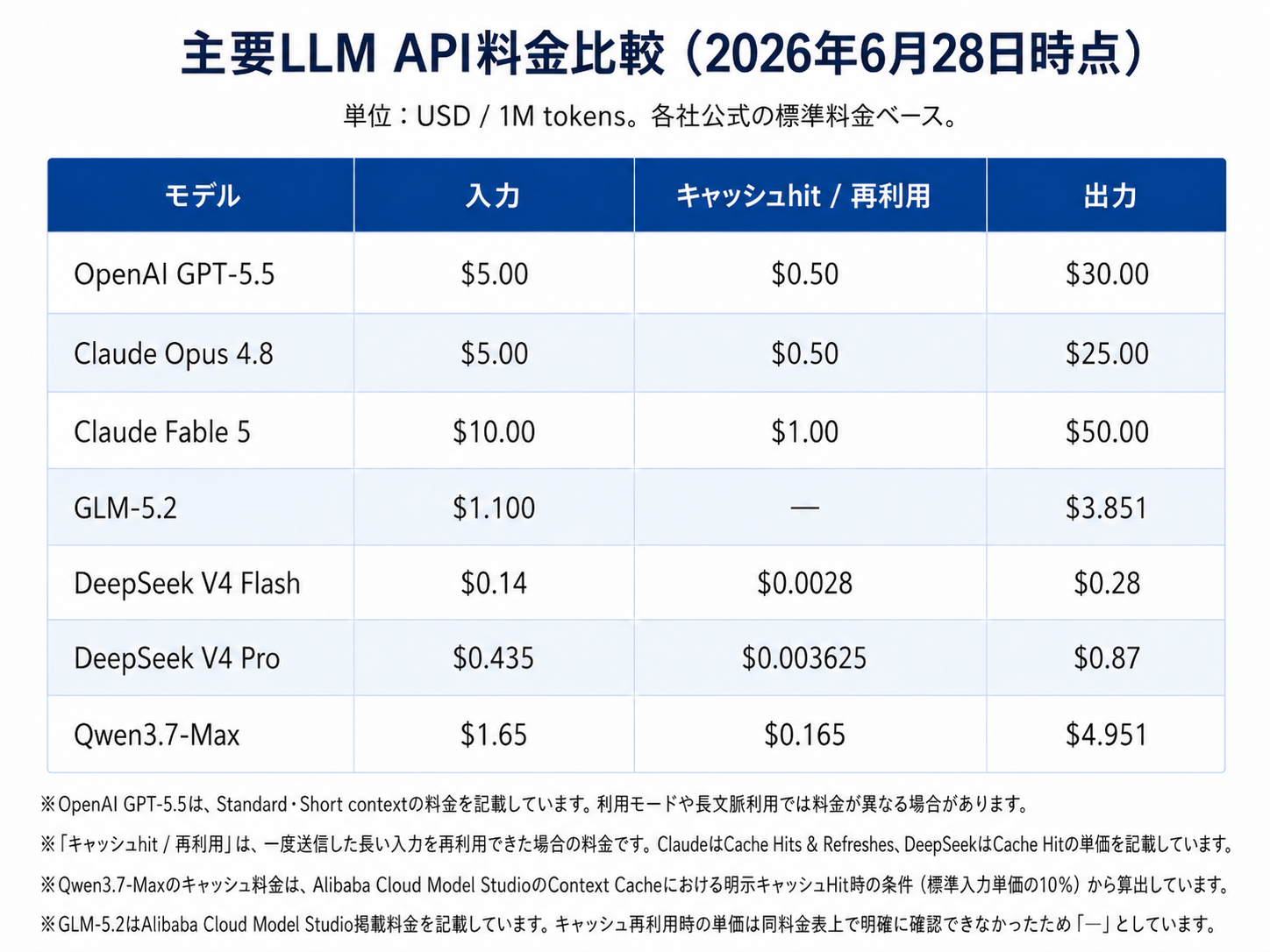
※料金は2026年6月28日時点で確認した公式情報をもとにしています。実際の料金、利用条件、提供状況は変更される可能性があるため、利用前に必ず各社の公式情報をご確認ください。
※Claude Fable 5については、Anthropicが2026年6月12日にアクセス停止を発表しています。表中の金額は料金情報として記載しており、実際の利用可否は掲載時点の公式情報をご確認ください。
※Claude Fable 5については、Anthropicが2026年6月12日にアクセス停止を発表しています。表中の金額は料金情報として記載しており、実際の利用可否は掲載時点の公式情報をご確認ください。
高性能LLMは便利ですが、API料金はモデルによって大きく異なります。
例えば、既存の高性能モデルでは100万トークンあたり数ドルから数十ドルの料金がかかる一方、中国発LLMの中には、出力単価が数ドル以下、入力単価が1ドル台またはそれ以下のモデルもあります。
特にDeepSeek V4 Flashのようなモデルは、キャッシュが効く場合の入力コストが低く、定型的な処理や大量の調査タスクでコストメリットが出やすい可能性があります。
また、GLM-5.2やQwen3.7系のモデルは、長いコンテキストやコーディング用途を意識して提供されており、AIコーディングの代替・補助モデルとして検討しやすい位置づけです。
ただし、価格だけで判断するのは適切ではありません。
安価なモデルであっても、出力品質が用途に合わなければ、レビューや修正にかかる人間のコストが増えます。
結果として、API料金は下がっても、開発全体のコストは下がらない可能性があります。
性能比較で注意すべきこと
LLMの性能比較では、ベンチマークの数字がよく使われます。
しかし、ベンチマーク結果だけで「このモデルが上」「このモデルが下」と判断するのは適切ではありません。
理由は、評価タスク、プロンプト、推論設定、ツール連携、エージェント実行環境によって結果が変わるためです。
特にAIコーディングでは、単発のコード生成能力だけでなく、既存コードの読み取り、修正方針の一貫性、テスト実行後の修正、長時間タスクでの安定性などが重要になります。
そのため、業務利用を検討する場合は、公開ベンチマークを参考にしつつ、自社の実際のタスクで小さく検証することが重要です。
例えば、以下のような検証が考えられます。
* 既存コードを読ませて仕様を説明できるか
* 小さなバグ修正を正しく行えるか
* テストコードを適切に追加できるか
* セキュリティ上危険な実装を提案しないか
* 長いやり取りでも前提を維持できるか
* レビューしやすい説明を出せるか
しかし、ベンチマーク結果だけで「このモデルが上」「このモデルが下」と判断するのは適切ではありません。
理由は、評価タスク、プロンプト、推論設定、ツール連携、エージェント実行環境によって結果が変わるためです。
特にAIコーディングでは、単発のコード生成能力だけでなく、既存コードの読み取り、修正方針の一貫性、テスト実行後の修正、長時間タスクでの安定性などが重要になります。
そのため、業務利用を検討する場合は、公開ベンチマークを参考にしつつ、自社の実際のタスクで小さく検証することが重要です。
例えば、以下のような検証が考えられます。
* 既存コードを読ませて仕様を説明できるか
* 小さなバグ修正を正しく行えるか
* テストコードを適切に追加できるか
* セキュリティ上危険な実装を提案しないか
* 長いやり取りでも前提を維持できるか
* レビューしやすい説明を出せるか
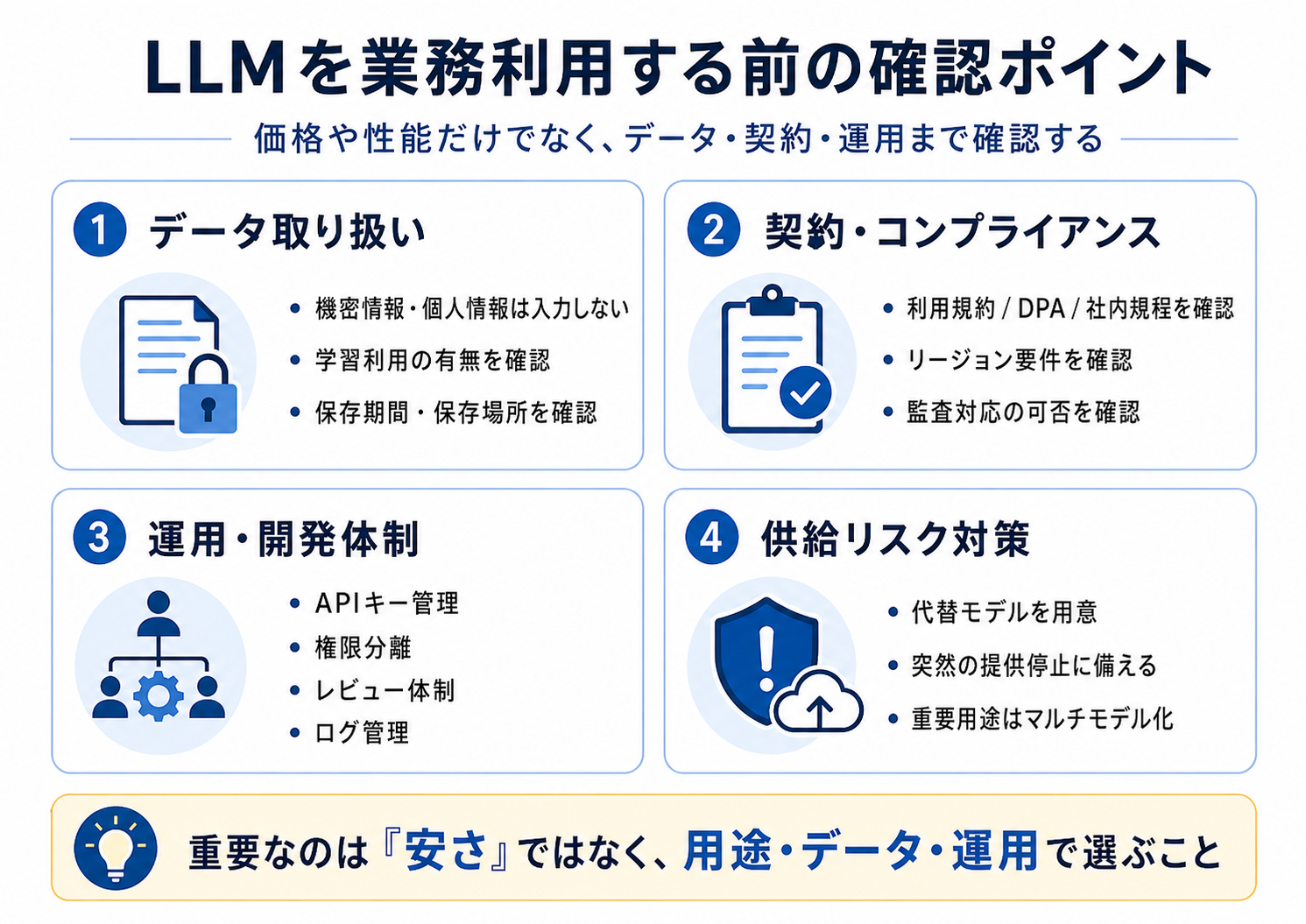
業務利用時の注意点
外部LLMを業務で利用する場合は、データの取り扱い、契約条件、社内規程、監査対応などを確認する必要があります。
ソースコード、顧客情報、設計書、障害ログ、APIキー、認証情報などは、絶対に許可なく外部LLMへ送ってはいけません。
これは中国発LLMに限った話ではなく、すべての外部AIサービスに共通する注意点です。
特に確認すべき項目は以下です。
* 入力データがどの国・地域で処理されるか
* 入力内容がモデル学習に使われるか
* 学習利用をオプトアウトできるか
* データ保持期間はどれくらいか
* 法人向け契約やDPAが用意されているか
* APIキーやアクセス権限を管理できるか
* 監査ログを取得できるか
* 生成物の著作権やライセンス条件に問題がないか
* オープンウェイトモデルの場合、商用利用や再配布の条件を満たしているか
* 社内規程や顧客契約に反しないか
また、高性能なモデルであっても、提供条件の変更、価格改定、利用制限、一時的なアクセス停止が発生する可能性があります。
実際にAnthropicは2026年6月12日、米政府の指示を受けてClaude Fable 5およびClaude Mythos 5へのアクセス停止を発表しています。
このような事例は、特定のモデルに業務プロセスを強く依存することのリスクを示しています。
AIコーディングや社内業務にLLMを組み込む場合は、メインで利用するモデルだけでなく、用途に応じた代替モデルや低コストモデルを用意しておくことが望ましいでしょう。
LLM選定では「最も性能が高いモデルを選ぶ」だけでなく、「用途に応じて複数の選択肢を持つ」ことが、コスト面でも運用面でも重要になります。
ソースコード、顧客情報、設計書、障害ログ、APIキー、認証情報などは、絶対に許可なく外部LLMへ送ってはいけません。
これは中国発LLMに限った話ではなく、すべての外部AIサービスに共通する注意点です。
特に確認すべき項目は以下です。
* 入力データがどの国・地域で処理されるか
* 入力内容がモデル学習に使われるか
* 学習利用をオプトアウトできるか
* データ保持期間はどれくらいか
* 法人向け契約やDPAが用意されているか
* APIキーやアクセス権限を管理できるか
* 監査ログを取得できるか
* 生成物の著作権やライセンス条件に問題がないか
* オープンウェイトモデルの場合、商用利用や再配布の条件を満たしているか
* 社内規程や顧客契約に反しないか
また、高性能なモデルであっても、提供条件の変更、価格改定、利用制限、一時的なアクセス停止が発生する可能性があります。
実際にAnthropicは2026年6月12日、米政府の指示を受けてClaude Fable 5およびClaude Mythos 5へのアクセス停止を発表しています。
このような事例は、特定のモデルに業務プロセスを強く依存することのリスクを示しています。
AIコーディングや社内業務にLLMを組み込む場合は、メインで利用するモデルだけでなく、用途に応じた代替モデルや低コストモデルを用意しておくことが望ましいでしょう。
LLM選定では「最も性能が高いモデルを選ぶ」だけでなく、「用途に応じて複数の選択肢を持つ」ことが、コスト面でも運用面でも重要になります。
業務外・学習用途で試す場合の注意点
外部LLMを業務で利用する場合は、データの取り扱い、契約条件、社内規程、監査対応などを確認する必要があります。
そのため、プロジェクトとしてすぐに導入するのが難しいケースもあります。
一方で、業務データを使わない範囲で、個人の学習や技術検証として特徴を把握することには価値があります。
特にAIコーディングの分野では、モデルごとの応答速度、コード理解力、修正提案の質、IDEとの相性などは、実際に触ってみないと分かりにくい部分があります。
例えば、以下のような用途であれば、比較的試しやすいでしょう。
* 公開されているサンプルコードを使った検証
* 個人で作成した小規模アプリの修正
* 架空の要件を使ったAPI実装の練習
* テストコード生成の比較
* エラー原因の調査能力の確認
* AIコーディング支援ツールとの相性確認
ただし、業務外の検証であっても注意点があります。
業務で扱うソースコード、顧客情報、設計書、障害ログ、APIキー、認証情報などを外部LLMに入力することは絶対にしてはいけません。
会社の許可を得ていない状態で、業務データを個人アカウントのAIサービスに入力すると、情報漏洩や社内規程違反となります。
そのため、個人で試す場合は、以下のようなルールを決めておくことが重要です。
* 業務コードや社内資料は入力しない
* 顧客名、個人情報、認証情報は入力しない
* 検証には公開情報または自作のサンプルを使う
* 実際の業務利用を判断する前に、会社のルールや契約条件を確認する
* 便利だった点だけでなく、不安だった点も記録する
個人利用は、あくまで「技術理解を深めるための検証」として位置づけるのが安全です。
業務利用に進める場合は、個人の体験だけで判断せず、社内のセキュリティ基準、契約条件、データ管理方針と照らし合わせて検討する必要があります。
AI活用では、実際に触ってみることも重要です。
ただし、業務データを守ることはそれ以上に重要です。
まずは業務データを使わない検証環境で特徴を把握し、そのうえで業務利用に耐えられるかを慎重に判断することが望ましいでしょう。
そのため、プロジェクトとしてすぐに導入するのが難しいケースもあります。
一方で、業務データを使わない範囲で、個人の学習や技術検証として特徴を把握することには価値があります。
特にAIコーディングの分野では、モデルごとの応答速度、コード理解力、修正提案の質、IDEとの相性などは、実際に触ってみないと分かりにくい部分があります。
例えば、以下のような用途であれば、比較的試しやすいでしょう。
* 公開されているサンプルコードを使った検証
* 個人で作成した小規模アプリの修正
* 架空の要件を使ったAPI実装の練習
* テストコード生成の比較
* エラー原因の調査能力の確認
* AIコーディング支援ツールとの相性確認
ただし、業務外の検証であっても注意点があります。
業務で扱うソースコード、顧客情報、設計書、障害ログ、APIキー、認証情報などを外部LLMに入力することは絶対にしてはいけません。
会社の許可を得ていない状態で、業務データを個人アカウントのAIサービスに入力すると、情報漏洩や社内規程違反となります。
そのため、個人で試す場合は、以下のようなルールを決めておくことが重要です。
* 業務コードや社内資料は入力しない
* 顧客名、個人情報、認証情報は入力しない
* 検証には公開情報または自作のサンプルを使う
* 実際の業務利用を判断する前に、会社のルールや契約条件を確認する
* 便利だった点だけでなく、不安だった点も記録する
個人利用は、あくまで「技術理解を深めるための検証」として位置づけるのが安全です。
業務利用に進める場合は、個人の体験だけで判断せず、社内のセキュリティ基準、契約条件、データ管理方針と照らし合わせて検討する必要があります。
AI活用では、実際に触ってみることも重要です。
ただし、業務データを守ることはそれ以上に重要です。
まずは業務データを使わない検証環境で特徴を把握し、そのうえで業務利用に耐えられるかを慎重に判断することが望ましいでしょう。
実務での使い分け例
AIコーディングでLLMを使い分けるなら、以下のような形が現実的です。
* 重要な設計判断:高性能モデルを使用
* 既存コード調査:低コスト・長文脈モデルを使用
* テストコード作成:低コストモデルを使用
* セキュリティレビュー:高性能モデルと人間レビューを併用
* ドキュメント作成:低コストモデルを使用
* 本番影響の大きい修正:AIだけに任せず、人間が必ず確認
このように、すべてを一つのモデルに任せるのではなく、作業内容に応じてモデルを使い分けることで、コストと品質のバランスを取りやすくなります。
* 重要な設計判断:高性能モデルを使用
* 既存コード調査:低コスト・長文脈モデルを使用
* テストコード作成:低コストモデルを使用
* セキュリティレビュー:高性能モデルと人間レビューを併用
* ドキュメント作成:低コストモデルを使用
* 本番影響の大きい修正:AIだけに任せず、人間が必ず確認
このように、すべてを一つのモデルに任せるのではなく、作業内容に応じてモデルを使い分けることで、コストと品質のバランスを取りやすくなります。
まとめ
AIコーディングの利用が広がるにつれて、LLMの選定では性能だけでなく、コスト、提供継続性、セキュリティ、データ管理を含めた総合的な判断が重要になっています。
DeepSeek、GLM、Qwenなどの中国発LLMを含む低コストLLMは、AIコーディングにおけるコスト課題に対する選択肢の一つです。
特に業務データを使わない学習や技術検証では、モデルごとの特徴や開発ツールとの相性を把握するうえで、有用な試行対象になります。
一方で、業務利用では価格や性能だけで判断してはいけません。
データの取り扱い、契約条件、保存地域、学習利用の有無、社内ルールとの整合性を確認する必要があります。
AI活用が進むほど、重要になるのは「単純なモデルの優劣」ではなく、「どの用途に、どのモデルを、どのデータ範囲で、どのルールに基づいて使うか」です。
業務データを使わない範囲で特徴を理解し、業務利用では安全性と運用体制を確認する。
この段階的な進め方が、LLMを無理なく活用するうえで現実的なアプローチといえるでしょう。
https://platform.openai.com/docs/pricing
https://docs.anthropic.com/en/docs/about-claude/pricing
https://api-docs.deepseek.com/quick_start/pricing
https://www.alibabacloud.com/help/en/model-studio/model-pricing
https://www.alibabacloud.com/help/en/model-studio/context-cache
DeepSeek、GLM、Qwenなどの中国発LLMを含む低コストLLMは、AIコーディングにおけるコスト課題に対する選択肢の一つです。
特に業務データを使わない学習や技術検証では、モデルごとの特徴や開発ツールとの相性を把握するうえで、有用な試行対象になります。
一方で、業務利用では価格や性能だけで判断してはいけません。
データの取り扱い、契約条件、保存地域、学習利用の有無、社内ルールとの整合性を確認する必要があります。
AI活用が進むほど、重要になるのは「単純なモデルの優劣」ではなく、「どの用途に、どのモデルを、どのデータ範囲で、どのルールに基づいて使うか」です。
業務データを使わない範囲で特徴を理解し、業務利用では安全性と運用体制を確認する。
この段階的な進め方が、LLMを無理なく活用するうえで現実的なアプローチといえるでしょう。
※料金比較表の出典
https://platform.openai.com/docs/pricing
https://docs.anthropic.com/en/docs/about-claude/pricing
https://api-docs.deepseek.com/quick_start/pricing
https://www.alibabacloud.com/help/en/model-studio/model-pricing
https://www.alibabacloud.com/help/en/model-studio/context-cache
※本記事に記載した製品名・サービス名は、各社の商標または登録商標です。料金・仕様・提供条件は変更される場合があります。


